
Datashare and Workbench: Experimenting Data journalism apps.
I got a bit of time to play around with two new data journalism tools that have been on my radar. They offer some interesting perspectives on data journalism

This week, I got a bit of time to play around with two new (to me) data journalism tools that have been on my radar.
The first was an out-of-the-box data journalism application called Workbench. The project is the brainchild of computational journalist Jonathan Stray and is backed by Columbia Journalism School. So what does it do? Well, according to the developers, it’s a data journalism platform with built-in training:
“Workbench is an integrated data journalism platform that makes it easy to assemble data scraping, cleaning, analysis and visualization tasks without any coding. You can load live data from the sources you already use, including open government portals, social media, SQL Databases, and Google Drive. Completed workflows can be shared along with the story to show audiences the story behind the chart.”
The application is available online at https://app.workbenchdata.com. Once you’re signed up (you can use Google or Facebook as well as email) and logged-in, you can dive right into a tutorial.
The tutorials follow a read > do > next format where you’re encouraged to go through steps, building up a ‘workflow’ for collecting, cleaning, filtering and visualising data. It’s impressive stuff and the tutorials cover a lot of ground very quickly. It also helps set up the concept of workflows that are the heart of Workbench.
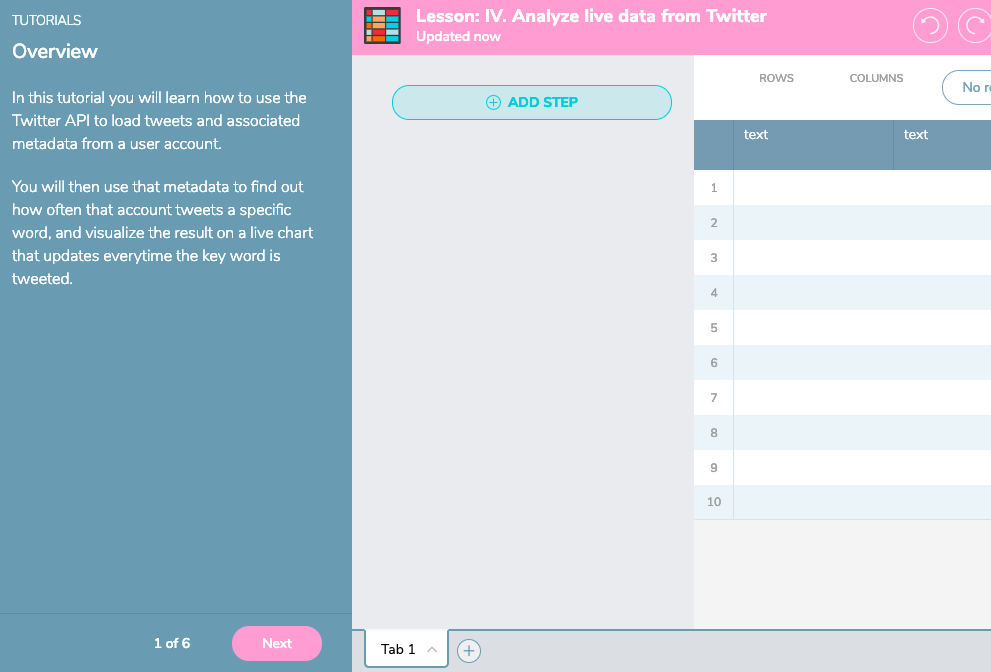
There are some predefined ‘recipes’ that you can copy and build your workflows on and if you’re not afraid to do a bit of clicking around (and use the undo function a few times!) to learn the way the app likes to work, then you can learn as much as you can from the tutorials. Once you have created a workflow, the open source nature of the platform means it should, in principle be easy to share it. Now the audience can see your working and colleagues can learn from your process.
I'm a bit late to the game here, as its been in development for a while. But it feels very mature and stable. As I played with workbench, and as I’m writing this now, I get a real sense of de ja vu. Workbench is a ‘bit like google sheets’ and ‘a bit like google fusion’. It’s got hints of IFTTT and some of it is ‘a tiny but Jupyter notebook’ . But this isn’t a bad thing, on the contrary. It means it’s shaping up to be a bit of a one stop shop for data driven reporting. I could easily see me recommending this as a good tool for some self-directed learning for students and journo’s alike.

The second app I tried this week was Datashare, built by the International Consortium of Investigative Journalists. Will Fitzgibbon from the ICIJ has a good overview of the motivation for creating Datashare:
Datashare is an application that allows you to efficiently search and organize your documents
Datashare is built on some of the same technology that helped ICIJ produce its biggest projects, like Panama Papers and Paradise Papers – but rather than rely on ICIJ’s servers, Datashare can be installed on your own computer.
Julien Martin offers a little more context (and a nice case study) of how Datashare does that
Datashare integrates ICIJ’s battle-tested Extract technology which pulls out machine-readable text from files (using Apache Tika), applies optical character recognition (Tesseract OCR) to images, then adds information to a search engine (Elasticsearch.)
In other words, you get an “out of the box” ICIJ toolbox for handling and managing large documents.
Unlike Workbench, Datashare is an application that lives on your computer rather than on the web. It makes sense; why have potentially sensitive documents floating around on the web? In fact future plans for the platform include ways for journalists to securely collaborate. It's technically serious stuff, and the workflow here is very much the multi-agency, deep dive model of investigative journalism. But don't be put off. The installer is great and the supporting documentation is excellent.
Once its installed - which can take a while - you need to move all your investigation documents into one folder. Then you pick Analyse my documents from the menu and you’re off.
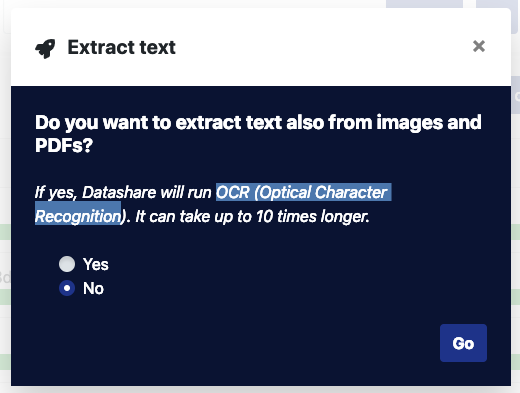
The first thing you can do is Extract text. This is great if you have a stack of PDF’s to work with and the choice to use OCR (Optical Character Recognition, although more time consuming, means you can get text from images of scanned documented too. The little progress bars slipped by quickly even on my old mac book air.
You can also Find people, organizations and locations in the documents. This uses natural language processing (NLP), a machine learning technique, that can analyse and extract information from, well ‘natural language’ . What’s really going on here is something called ‘entity extraction’ which pulls out chunks of content and tries to categorise them.
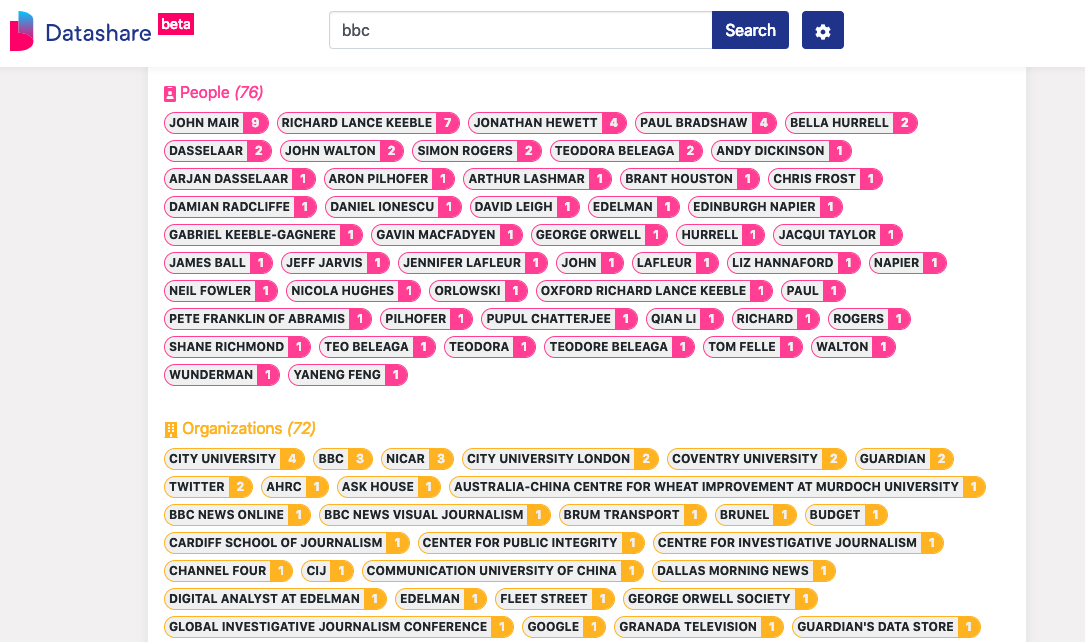
This is great for document level work but even better to connect names, places and orgs across documents. Who appears where and in what context helps build up a picture of connections.
It’s clear that Datashare is aimed at those with something more meaty investigate. For the casual experimenter, it’s an interesting window in to the tools of the trade of orgs like ICIJ.I hope that future tools in the kit will include ways of visualising these connections. But ultimately, the core of what Datashare does is as a workhorse for turning your documents into structured data.
If I had a more immediate suggestion for the app develops, it would be to add a ‘my documents’ button to the menu. It's quite hard to find the docs you add. I know it would be something that the hardcore users wouldn’t need — it’s all about what’s in the documents rather than the documents themselves. I also know that it would be a bit of a sop to people like me who don't RTFM until they get stuck. But it would help ease in the explorers and really wouldn't be any more than a link, say to 'my doc store' or 'files' for example.
Conclusions
If you have a passing interest in computational, data journalism or investigative journalism, I’d really recommend a play with both. I think a lot of people might be pleasantly surprised at what you can do with Workbench. It's definitely more than a learn by doing platform. There's some useable tools here and sufficient extensibility to distract the 'but I can just do that in python' critic. Don’t let the slightly more austere and technical nature of DataShare put you off. As I said, the Datashare User Guide is excellent.
Both apps offer an interesting peak into the way data journalism practices are developing in terms of technology and complexity - that alone is a good reason to play. They also perhaps represent a kind of recognition of this and the concerns we may have about the capacity for journalism to keep pace. But that’s something to ponder for another blog post. For now, give them a go and give them your feedback.